Categorical annotation rows
1 General
- Type: - Matrix Processing
- Heading: - Annot. rows
- Source code: CreateCategoricalAnnotRow.cs
2 Brief description
Manage the categorical annotation rows. One important applications is to define a grouping that is later used in a t-test or ANOVA.
Output: Same matrix with categorical annotation rows added or modified.
3 Parameters
3.1 Action
Defines the action that should be applied to a categorical annotation row (default: Create). The action can be selected from a predefined list:
- Create
- Create from experiment name
- Edit
- Rename
- Delete
- Write template file
- Read from file
Each of the above listed options has different parameters, which are explained below in more detail and grouped according to the action.
3.1.1 Create
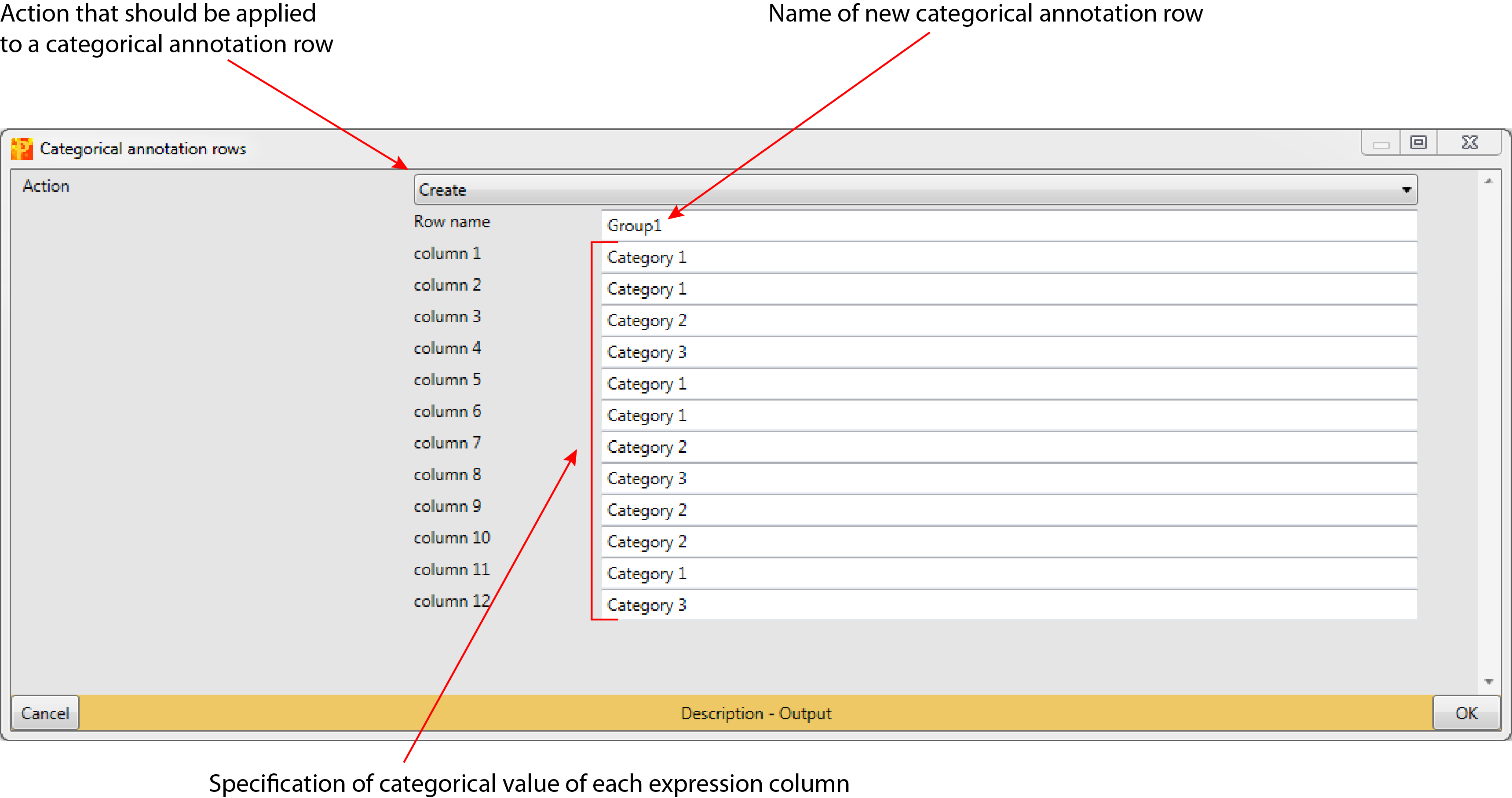
3.1.1.1 Row name
This parameter is just relevant, if “Action” is set to “Create”. It defines the name of the new generated categorical annotation row (default: Group1).
3.1.1.2 Here: Column 1 … Column 12
This parameter is just relevant, if “Action” is set to “Create”. For each of the expression columns in the matrix the category value of that column in the categorical annotation row can be specified (default: each expression column has its own category indicated by the name of the expression column).
3.1.2 Create from experiment name
3.1.2.1 Pattern
This parameter is just relevant, if “Action” is set to “Create from experiment name”. It specifies the pattern that will be applied to the column names to group the columns and generate a new categorical annotation row (default: …_01,02,03). The Pattern can be selected from a predefined list:
- …_01,02,03
- (LFQ) intensity …_01,02,03
- (Normalized) ratio H/L …_01,02,03
- match regular expression
- replace regular expression
3.1.2.2 Regex
This parameter is just relevant, if “Action” is set to “Create from experiment name” and the parameter “Pattern” is set to “match regular expression” or “replace regular expression” (default: empty text field). Here a regular expression can be typed in, which should be applied to the column names to group the columns. The general rules for regular expressions apply here.
3.1.2.3 Replace with
This parameter is just relevant, if “Action” is set to “Create from experiment name” and the parameter “Pattern” is set to “replace regular expression” (default: empty text field). Columns matching the defined regular expression in the field “Regex” get the value specified in the “Replace with” field and are therefore grouped.
3.1.3 Edit
3.1.3.1 Category row
This parameter is just relevant, if “Action” is set to “Edit”. It specifies the selected categorical row that should be edited (default: first categorical column in the matrix).
3.1.3.2 Here: Column 1…Column 12
This parameter is just relevant, if “Action” is set to “Edit”. For each of the expression columns in the matrix the value in the categorical row can be edited by typing into the defined text field after the column name (default: category values of each expression column in that row).
3.1.4 Rename
3.1.4.1 Category row
This parameter is just relevant, if “Action” is set to “Rename”. It specifies the selected categorical row that should be renamed (default: first category row in the matrix).
3.1.4.2 New name
This parameter is just relevant, if “Action” is set to “Rename”. It defines the new name of the categorical row (default: empty).
3.1.4.3 New description
This parameter is just relevant, if “Action” is set to “Rename”. It defines the new description of the categorical row (default: empty).
3.1.5 Delete
3.1.5.1 Category row
This parameter is just relevant, if “Action” is set to “Delete”. It specifies the selected categorical row that should be deleted (default: first category row in the matrix).
3.1.6 Write template file
3.1.6.1 Output file
This parameter is just relevant, if “Action” is set to “Write template file”. It specifies the file name and path, where a grouping template of a categorical annotation rows is saved in a tab separated text file (default: Groups.txt). The first column of the output file is named “Name” and contains the names of the columns. The second column has the column names as values and can be edited manually. After editing the file can be read using “Read from file” (see below).
3.1.7 Read from file
3.1.7.1 Input file
This parameter is just relevant, if “Action” is set to “Read from file”. It defines the file name and path of a tab separated file containing information about a new grouping of the columns of a matrix (default: empty). The first column is called “Name” and contains the names of the columns of the matrix. The second column has the name of the new grouping and contains the values of each column of the matrix.
4 Parameter window